End-to-end customer segmentation pipeline using RFM scoring and K-Means clustering — implemented across 3 languages: SQL for data extraction, Python for machine learning, and Go for the segment reporting CLI.
Pipeline de segmentacion de clientes de extremo a extremo usando puntajes RFM y clustering K-Means — implementado en 3 lenguajes: SQL para extraccion de datos, Python para machine learning y Go para el reporte CLI.
| Metric | Definition | Business meaning |
|---|---|---|
| R — Recency | Days since last purchase | Active customers buy more |
| F — Frequency | Number of distinct orders | Loyal customers order often |
| M — Monetary | Total spend | High-value customers drive revenue |
Each metric is scored 1–5 using quantile ranking (NTILE logic), giving each customer an RFM score from 3 to 15.
| Language | Role | Libraries |
|---|---|---|
| SQL | RFM scoring query (NTILE window functions) | PostgreSQL / MySQL 8+ / BigQuery / DuckDB |
| Python | ML pipeline: RFM scoring + K-Means clustering | Pandas · Scikit-learn |
| Go | Segment reporter CLI — fast, zero dependencies | stdlib only |
Customer-Segmentation-RFM/
├── sql/
│ └── rfm_query.sql # NTILE-based RFM scoring in pure SQL
├── python/
│ ├── 01_rfm_scoring.py # Compute RFM metrics and 1-5 scores
│ └── 02_clustering.py # K-Means segmentation + business labels
├── go/
│ ├── segment_report.go # CLI: segment summary table + revenue bars
│ └── go.mod
├── data/
│ └── customer_transactions.csv # 2,272 transactions | 200 customers
└── README.md
pip install pandas scikit-learn
python python/01_rfm_scoring.py # generates data/rfm_scores.csv
python python/02_clustering.py # generates data/customer_segments.csvcd go
go run segment_report.go --file ../data/customer_segments.csv
# Filter to a specific segment / Filtrar por segmento
go run segment_report.go --file ../data/customer_segments.csv --segment "At Risk"# Run rfm_query.sql against your database with a customer_transactions table
# Ejecuta rfm_query.sql contra tu BD con una tabla customer_transactions
psql -d mydb -f sql/rfm_query.sqlResults computed on the included dataset: 200 customers · 2,272 transactions · $140,132 total revenue
Resultados calculados sobre el dataset incluido: 200 clientes · 2,272 transacciones · $140,132 de revenue total
| Metric | Value | Interpretation |
|---|---|---|
| Silhouette Score | 0.4046 | Good cluster separation (0=bad, 1=perfect) |
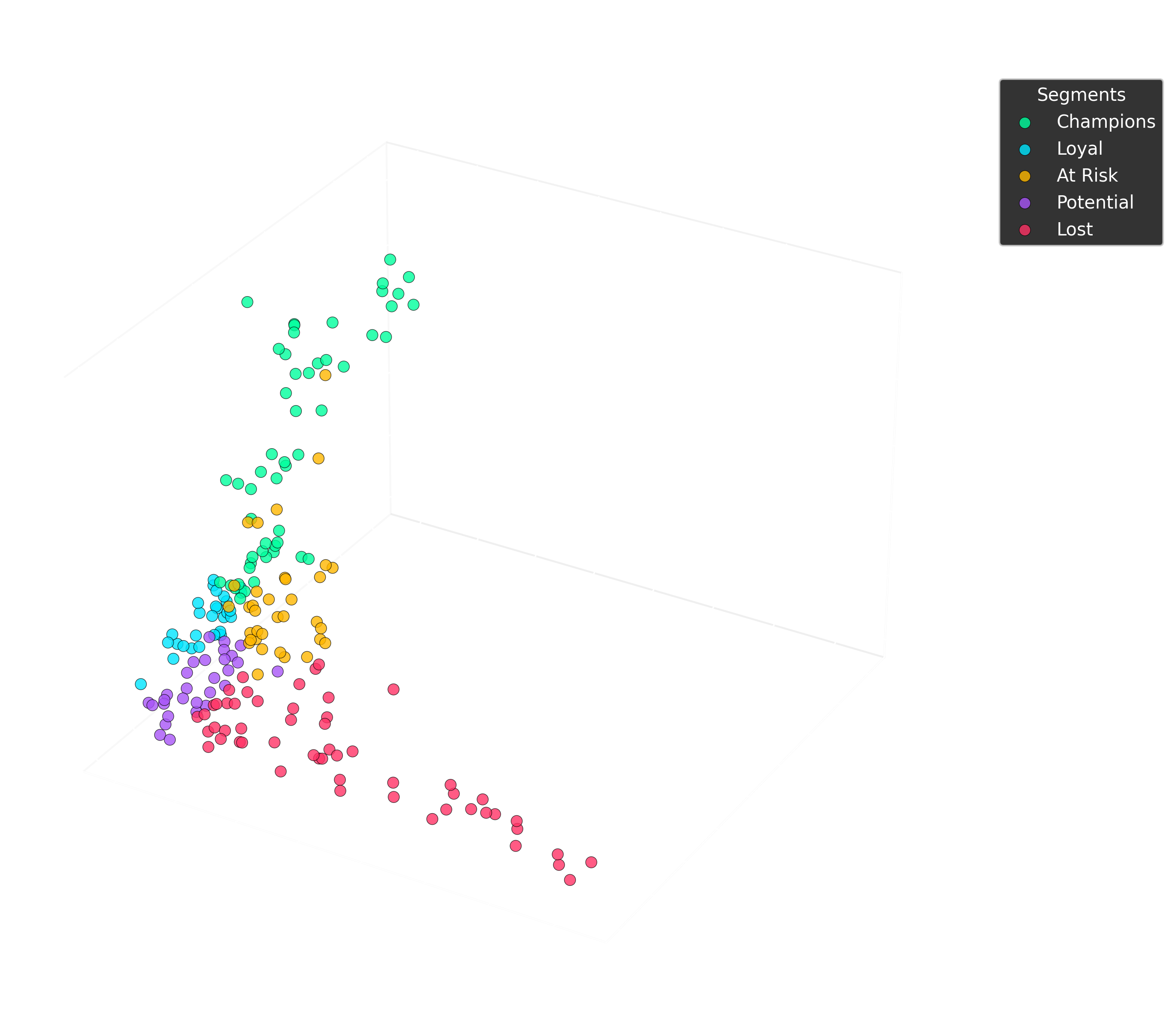
| k (clusters) | 5 | Champions · Loyal · At Risk · Potential · Lost |
| Init method | k-means++ | Optimized centroid initialization |
| n_init | 20 | 20 random starts for stability |
| Segment | Customers | % Customers | Avg Recency | Avg Orders | Avg Spend | % Revenue |
|---|---|---|---|---|---|---|
| Champions | 53 | 26.5% | 26 days | 22.0 | $1,410 | 53.3% |
| At Risk | 35 | 17.5% | 105 days | 12.7 | $745 | 18.6% |
| Loyal | 29 | 14.5% | 14 days | 10.1 | $555 | 11.5% |
| Lost | 54 | 27.0% | 307 days | 3.7 | $268 | 10.3% |
| Potential | 29 | 14.5% | 48 days | 6.0 | $303 | 6.3% |
26.5% of customers (Champions) generate 53.3% of total revenue. Classic 80/20 rule: protect and invest heavily in this segment.
El 26.5% de los clientes (Champions) generan el 53.3% del revenue total. Regla 80/20 clasica: protege e invierte fuertemente en este segmento.
| Segment | EN Action | Accion ES |
|---|---|---|
| Champions | Reward them, ask for referrals, make them brand ambassadors | Recompensalos, pide referidos, conviertelos en embajadores |
| Loyal | Upsell premium products, enroll in loyalty program | Ofrece productos premium, enrolla en programa de lealtad |
| At Risk | Send win-back email campaign + limited-time discount | Campana de recuperacion por email + descuento por tiempo limitado |
| Potential | Nurture with onboarding emails, product recommendations | Nutre con emails de onboarding y recomendaciones de productos |
| Lost | Strong re-engagement offer or exit survey | Oferta fuerte de reenganche o encuesta de salida |
The sql/rfm_query.sql file implements the same logic using pure SQL window functions — ideal for production environments with millions of rows in a data warehouse.
El archivo sql/rfm_query.sql implementa la misma logica usando funciones de ventana SQL puras — ideal para entornos de produccion con millones de filas en un data warehouse.
-- NTILE scoring example / Ejemplo de puntaje NTILE
NTILE(5) OVER (ORDER BY recency_days DESC) AS r_score, -- 5 = most recent
NTILE(5) OVER (ORDER BY frequency ASC) AS f_score, -- 5 = most frequent
NTILE(5) OVER (ORDER BY monetary ASC) AS m_score -- 5 = highest spendJulian David Urrego Lancheros Data Analyst · Python Developer · Marketing Science GitHub · juliandavidurrego2011@gmail.com